The voices of hate in this climate "debate" will be pleased to know that their enemy Michael Mann had "
nightmares of a dystopian future — think Soylent Green or Mad Max". Mann told this Fusion for their story titled "
These people are literally having climate change nightmares".
In the same story Dahr Jamail, a reporter who covers climate change, also recalls a quite dramatic nightmare: "
It was simply a vision of a future Earth that was mostly barren of biological activity, one scarred by resource wars, and having seen a massive die off of humans, given we are already well into the sixth mass extinction event."
On Reddit a father wrote: "
I have a 10 week old son and I'm terrified of his future. 4 years of actively ignoring climate change could mean never recovering. ... I'm just terrified." I prefer not to link to it, but someone even wrote to have suicidal thoughts because of climate change.

Climate change is a serious problem, but I see no need for such despair. We are on our way to solving the climate crisis. I do understand why people in America feel more despair being confronted daily with the most insane denial that climate change is a problem.
That is a classic nightmare. You are in a car sitting next to Lamar Inhofe behind the wheel. You see a cliff at the end of the road and try to warn Anthony Goddard that he should break. Instead Tim Delingpole speeds up because "gasoline is life", claims that cars are a product of the free market, that thus nothing can be wrong with them and Malcolm Nova turns the radio extra loud to make conversation impossible. You shout and shout, but the cliff gets closer and closer. You shout so loud that you lose your voice. The second part of the nightmare where you fall down an infinitely deep cliff is more relaxing.
Albeit it does move
My feeling is that many people are flipping out because they have the feeling nothing is done to combat the problem. Now already for over 3 decades. This is amplified by completely crazy people denying the most basic and solid facts as a way to avoid an adult conversation about solutions. If we would not act, the situation would become dire. Especially if we would react with the same denial, stupidity and anger to the problems created by climate change: New Orleans 2.0, climate refugees and conflicts over water. If that is your assessment of the situation, it is natural to be very worried.
I am more relaxed because I have the feeling we are acting. It helps that live in Germany were nearly all people are reasonable, including the conservatives. Even the people in my life who identify as climate "sceptics" are mostly reasonable. They just want so much climate change not to be happening and most are irrationally hopeful to one day find the "error", but they do not produce bullshit on an industrial scale like American blogs and think tanks.
Only the German racists deny there is a problem. It could always be even better, but Germany is part of the solution. That gives me a different perspective. I do not look at the continually increasing CO2 concentrations and temperatures, but at the enormous growth rates of renewable energy and the clear improvements in energy efficiency.
A lot is happening already.
The last 3 years the emissions from industry and fossil fuels were stable, that used to happen only during world-wide recessions. That is a sign that renewable energy and energy efficiency policies and technology are starting to work. Most of the global new power generating
capacity and investments are already carbon free. The next step is that also most new
production is renewable, then we need to
electrify the rest of the economy and use the market and technology to bring supply and demand together. It is still a long way, but I feel it is moving.

If anyone had a nightmare the last week, Donald Bannon likely had weird orange hair. Then it is important to realise that America is no longer that important.
To quote myself:
The main question is whether America's refusal to act will reduce the willingness to act in the rest of the world. America by itself is no longer a major player and only emits 16% of all greenhouse gasses. Inaction in America is thus bad, but if limited to several years, and Trump is 70, a limited problem. The emissions should be zero in 2050. The danger is when this goes on for too long and when the rest of the world would be discouraged from acting or when international conflict makes global collaboration impossible.
Especially after the global climate conference in Marrakesh, we can
realistically hope that the rest of the world will stay on course. The world is united to defy Trump's climate threat. The Marrakesh Action Proclamation says
every country has an "urgent duty to respond". Many countries
are fighting back. The French presidential candidate just threatened America with a carbon import tariff of a 1 to 3% on US goods. Sounds reasonable and
is allowed likely to be technically possible by the international (WTO) trade rules. The Paris treaty can be updated so that the more climate-conscious economic power houses in the USA, such as California and New York, could join.
European Union Climate Commissioner Miguel Arias Canete said: "
The world is on the brink of an energy revolution." The rest of the world may well see it as a great business opportunity that the USA is missing out on the technologies that will shape the next century in this critical moment. Maybe Trump will even speed up the international energy transition.
The oil companies ExxonMobile and
BHP Billiton have asked Trump to accept the Paris climate treaty.
Next to 360 other big businesses and investors. Even petrostate Saudi-Arabia has less problems with [[
corporate capture]] than the US Republican party and welcomes the Solar Age.
Republican spokesman Bill O'Reilly seems to fear a backlash and said on his television show that
Trump "should accept the Paris Treaty on climate to buy some goodwill overseas".

The state of the climate
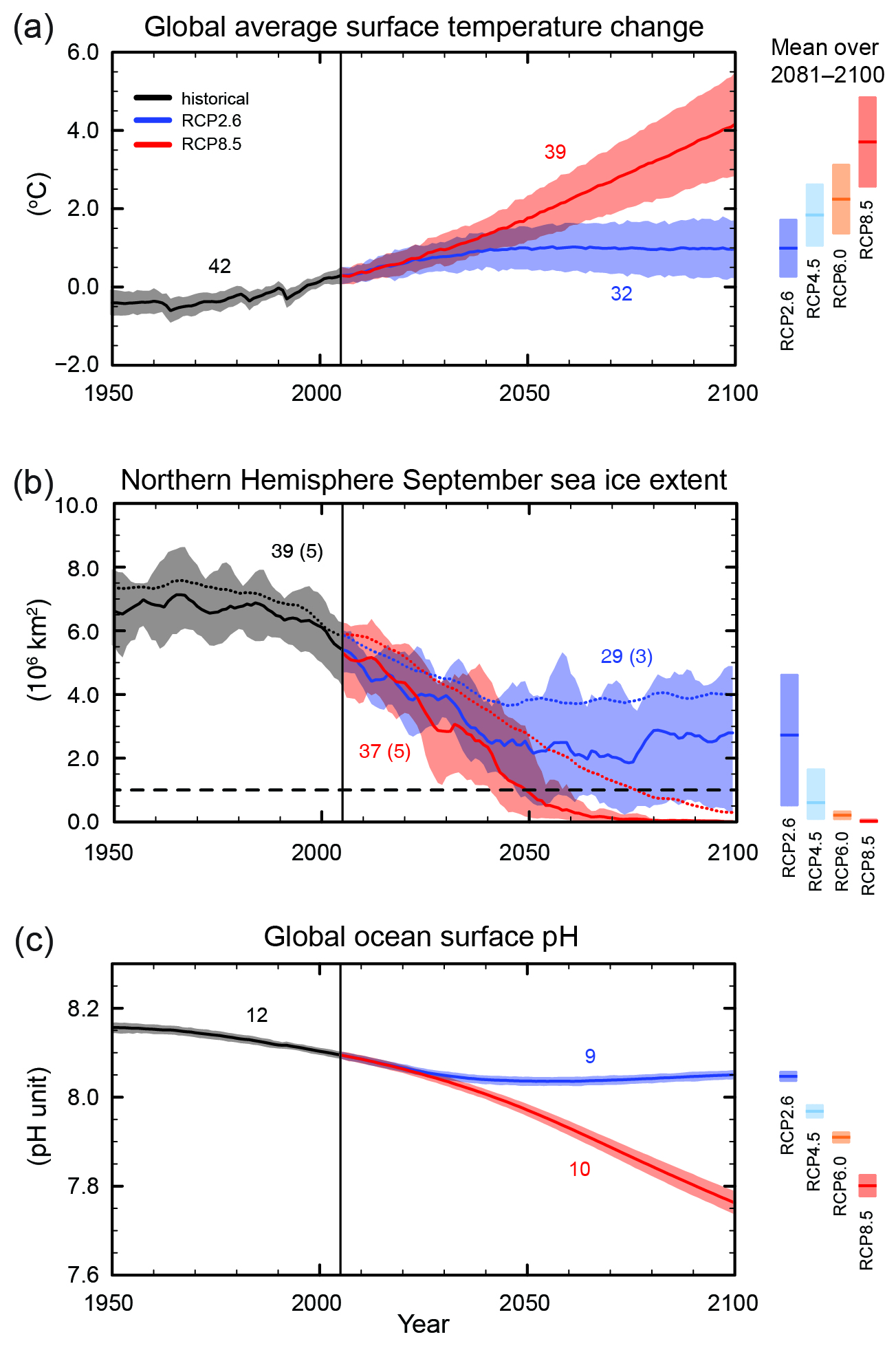
But, let's take a step back. Some people worry about 4°C of warming or more with the justified nightmare scenarios that come with it. 4°C for 2100 and more afterwards is what science expects
in case of no action. The figure from the IPCC report's summary for policy makers show
no action in red and a
very optimistic action scenario in blue.

The
Climate Action Tracker expects a warming in 2100 of 3.6°C with current policies and of 2.6°C if countries stick to their Paris pledges (Intended Nationally Determined Contributions; INDCs). The
United Nations Environment Programme (UNEP) estimates that the pledges would mean between 2.9 and 3.4°C by the end of this century. A recent study published in Nature projects warming
between 2.6-3.1°C in 2100 with Paris pledges.
The big unknown is what countries will do beyond 2030. The Paris pledges do not go beyond 2030, but first countries have started defining their goals for 2050. The idea of Paris is that every 5 years the pledges become stronger if that is necessary. In that respect one should mainly look whether the next years are more or less on track.
Citizens of the world will have to demand of their governments to make these promises reality, but I feel it is fair to say that the worst worst-case scenarios are off the table. With Trump's election some of the best-case scenario's are unfortunately also less likely. I still have my personal best-case scenario where renewable energy becomes so inexpensive that the carbon bubble bursts and the Paris promises on energy are over-fulfilled without any further government action.
I might be too optimistic, but I think we already passed the point where solving the problem has become inevitable. It sounds like top economist and Bernie Sanders adviser
Jeffrey Sachs shares my assessment:
The transition to renewable energy has passed a tipping point. A positive tipping point.
Technological and organizational progress is going rapidly and makes
energy efficient technologies and renewable energy much less expensive. The graph below shows the numbers for technological improvements from the US Department Of Energy (DOE).

And
no, there is no price saturation in sight. It may look that way in the above graph because we will not get to zero; the same percentage gains at the end looks smaller because the costs themselves are lower.
The logarithmic plot below shows prices keep dropping.

At the end of 2015, renewable capacity in place was enough to supply an estimated
23.7% of global electricity, with hydropower providing about 16.6%. Most important are likely solar and wind, they grow fastest and have the largest potential. At the moment they are at 1.4% of the world’s final energy consumption. That means that now the rest of the energy sector starts to notice their growth, which were the corporate resistance in the US comes from.
Wind is growing by 14% every year and solar by 20%. 20% growth means doubling every 4 years, that is powerful growth. If we can keep that up that would mean: 1% (now), 2% (2020), 4% (2024), 8% (2028), 16% (2032), 32% (2036). It will likely gradually slow down, but it shows that it is possible to arrive at 100% soon, hopefully in 2050.
Mainstream environmental organizations such as
Greenpeace and
Friends of the Earth aim for zero CO2 emissions in 2050. The Paris treaty wants to achieve this in the second half of the century, while now in Marrakesh 47 developing countries have pledged that
they would get all their energy from renewable sources before 2050.
The group Climate Mobilization pledges to fight for
100% reduction in CO2 emission in the USA in 2025. That would be fast and thus more costly. Personally I would be happy to pay that price, already for the clean air and to see less species going extinct. This mobilization could be a response to the insane radicalization of the US anti-environmental movement.
Economist Jeffrey Sachs also expects that the U.S. will become a pariah state if Trump pulls out of Paris Climate Accord. That comes on top of the power loss from having an incompetent uninterested buffoon as president, a president that cannot give security guarantees because he likes to renegotiate deals, the damage to the US from cancelling the hard-fought global agreement on Iran's nuclear power program, and the transfer of power to China if the TPP is cancelled. Let's see if wrecking the climate is so dear to Trump that he is willing to pay that price. That is probably what Bill O'Reilly fears. That could mean less
fresh and joyous wars and less dead Muslims. Let's see if Trump is willing to pay this price.
We had about 1°C of warming since 1900. Thus we are about halfway to the internationally agreed 2°C limit.

It will take time to transform the energy system, this is infrastructure that is build to work for decades, and the warming would continue for some time if we abruptly stopped emitting CO2. Because of the heat capacity of the oceans we are not at the equilibrium temperature yet that corresponds to the current CO2 concentrations; like it takes time until a water kettle boils because of the heat capacity of the water.
Combustion of fossil fuels produces tiny airborne particles (aerosols), which cool the temperature somewhat, once we stop with fossil fuels this would produce a little warming (~0.2°C).
If you take these delays into account, it will be work to stay below 2°C, but it is still possible to stay below it. One reason some people are freaking out is because some speak as if this 2°C level is a brick wall. This is not true. This limit is a political compromise. If changing the energy system were easy, we would have agreed on no more than 1°C or even less long time ago. It is a compromise between the costs of a fast transition and the costs of adaptation and the damages due to climate change.
I would personally have preferred a more ambitious compromise, but there is no brick wall or cliff at 2°C. Climate change will gradually become more risky. Similarly, it would reduce the risk if we could stay well below 2°C.

Climate change is a stressor. An important one because it stresses so many things that are important to us. Like climate change itself, these problems are solvable, we just need the political will to do so. What the impacts will thus be also depends on whether humanity gets its act together. If people like Trump are in power a Mad Max scenario is a much higher risk.
Another reason to freak out can be that the media, when they are not in denial, often over-hypes problems. A sane middle seems hard to find in the USA. To improve your information diet old fashioned books are the best place to start.
RealClimate, a blog by actual climate scientists, and the information resources they point to, is also good start. To see whether current stories in the media hold up to scrutiny you can have a look at
Climate Feedback, a collaboration of climate scientists fact checking stories in the media.
What to do?
Much anxiety comes from feeling helpless to do something. Thus being part of the solution reduces anxiety. Join an environmental group. If only to see there are like minded sane people. Very encouraging was that I have seen many people on Reddit asking what they can do.
If enough people stand up, the net effect of the Trump shock could even be positive.
The US political system is a mess. We need to get money out of US politics. Trump will make this worse. He is already packing his cabinet with lobbyists. His tax plans and deregulation will further increase inequality, increase the power of the wealthy and give them more money to corrupt the political process.
I like Wolf PAC, but there are many other groups working on this. Join the Democrat party (with some friends) and try to throw the corporatists out.
Banks are starting to worry about their influence on society. Bloomberg reports: "
Rise of Populism Tops Anxiety List at Frankfurt Banking Meeting." They could stop bribing US politics and stop working for corporations that do this. Until they do so, join an
ethical bank; their rates are competitive. I love mine.
When it comes to climate change itself,
join 350 to divest fossil fuel companies. With the renewable energy age so close and the remaining carbon budget not allowing for new fossil fuel infrastructure, the economic case against fossil fuel investments is stronger than ever. New infrastructure that would need to be profitable for decades, well after Trump is dead.
Hopefully the states, cities, private sector and citizens will pick up the pace to compensate for the counter-productive behaviour of the federal government. It is likely more productive to focus on solutions and not climate change itself. Denying climate change has become part of their identity for many Republicans. There are no arguments that could convince these people to change their public position. However, renewable energy is, for example, immensely popular with everyone, also with Republicans. There are even green tea parties against attempts of state governments to help their cronies in the utilities and make it more difficult to install solar on the roofs of homes.

If you have money, investing in renewable energy (in the USA) now will be more useful than ever. It would decrease the market for new fossil fuel infrastructure and support solar and wind companies over the Trump bump. I would be surprised if anyone would start to plan for a new coal power plant at this time. It takes a long time until it is running and would need to run a long time. Trump is 70 years old and will not be around forever and after that the investment will make losses. Maybe even before that because of cheap gas and renewables.
The energy sector is nowadays only 6% of the global economy; it is thus easier than one may think to move it. Once wind or solar is running, nothing can compete with their marginal costs. The best way would be to join or start an
energy cooperative with your friends and family. That gets more people involved.
Climate change is solvable and I am confident we will. The real problem, the big problem is not climate change. It is us, as Prince EA beautifully explains below.
Related reading
Hope Jahren sure can write:
What I Say When People Tell Me That They Feel Hopeless About Climate Change
Jessika E. Trancik (MIT associate professor):
People are worried Trump will stop climate progress. The numbers suggest he can’t.
Luke Kemp:
US-proofing the Paris Climate Agreement in Climate Policy, doi:
10.1080/14693062.2016.1176007
Informative clear overview of what happened in Marrakesh by Guardian's Graham Readfearn:
Marrakech climate talks wind down with maze of ambition still ahead
Donald Trump actually has very little control over green energy and climate change.
“Market forces, not the government” are responsible for the fact that wind and solar power are replacing coal.
Chart of the year: ‘Incredible’ price drops jumpstart clean energy revolution
A view from Germany on Trump's America
Climate Denial Crock of the Week by Peter Sinclair:
New Video: Report from COP22 – Still a Way Forward
* Post Apocalypse by 70023venus2009 used under a Attribution-NoDerivs 2.0 Generic (CC BY-ND 2.0) license.
* Make Climate Great Again photo by Takver used under a Attribution-ShareAlike 2.0 Generic (CC BY-SA 2.0) license.
* We're Still In photo by Takver used under a Attribution-ShareAlike 2.0 Generic (CC BY-SA 2.0) license.
* Afternoon Traffic - Cycling in Winter in Copenhagen by Colville-Andersen used under a Attribution 2.0 Generic (CC BY 2.0) license.
* Photo train by Arne List used under a Attribution-ShareAlike 2.0 Generic (CC BY-SA 2.0) license.